HDFS VS Apache Ozone
Tabular differences based on the features
| Feature | HDFS | Apache Ozone |
|---|---|---|
| Data Model | Blocks | Objects |
| Data Replication | 3 copies of each block | Erasure Coding |
| Scalability | Limited by the number of NameNodes | Scales horizontally with more Ozone Managers added |
| Namespace Management | Single namespace for the entire cluster | Multiple namespaces for different use cases |
| Object Storage | No | Yes |
| Support for S3 and other object storage protocols | No | Yes |
| Access Control | POSIX-style permissions | S3-style permissions and bucket-level access controls |
| Authentication and Authorization | Kerberos-based | Token-based (Ozone Token) |
| Data Consistency | Eventual consistency | Strong consistency |
Tabular differences based on the Principles
| Principles | Apache Ozone | HDFS |
| Definition |
Ozone is an object store designed for big data applications. Big data workloads tend to be very different from standard workloads and Ozone is born out of lessons learned from running Hadoop in thousands of clusters. |
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run on commodity hardware.HDFS is highly fault-tolerant and is designed to be deployed on low-cost hardware. |
| Architecture |
|
|
| Data Storage |
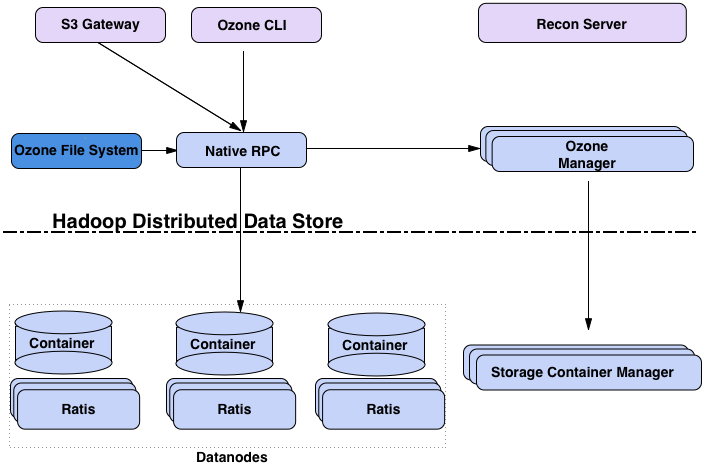
Ozone File System (OzoneFS) is a Hadoop compatible file system. Applications like Hive, Spark, YARN, and MapReduce run natively on OzoneFS without any modifications. OzoneFS resides on a bucket in the Ozone cluster. All files created through OzoneFS are stored as keys in this compartment. All keys created in the particular bucket without using file system commands are displayed as files or directories on OzoneFS. |
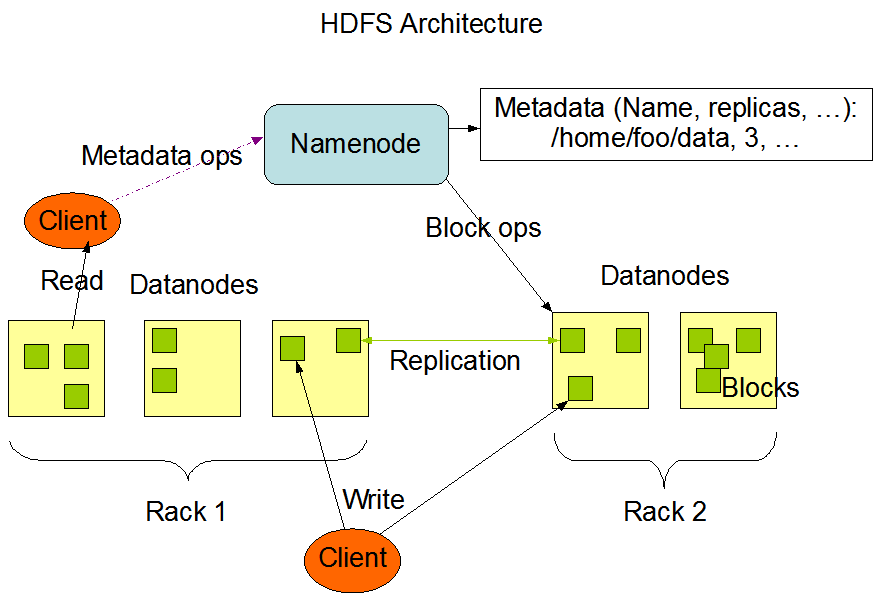
HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes |
| – | Ozone is a distributed key-value store that can manage both small and large files | HDFS provides POSIX-like semantics |
| Open Source | Yes | Yes |
| Scalable | Yes | Yes |
| Recovery | Ozone is also robust in the face of failures. | A key strength of HDFS is that it can effectively recover from catastrophic events like cluster-wide power loss without losing data |
| Small File Problem | Ozone is a distributed key-value store that can manage both small and large files alike | HDFS works best when most of the files are large – tens to hundreds of MBs. HDFS suffers from the famous small files limitation and struggles with over 400 Million files. |
| Latest Stable Version | 1.2.0 | 3.3 |
| Key Commands | get put delete info list |
get put mkdir ls rm |
| Supports Application |
Ozone File System (OzoneFS) is a Hadoop-compatible file system. Applications such as Hive, Spark, YARN, and MapReduce run natively on OzoneFS without any modifications. |
Supports Many Application including Hive, Spark , Mapreduce , HBase.. etc |
Ozone Architecture