Streaming Showdown: Comparing Apache Pulsar and Apache Kafka’s Architecture, Performance, and Use Cases
Apache Pulsar and Apache Kafka are both open-source distributed systems that are designed to handle high-performance, low-latency streaming data. However, they have different architectures and use cases.
Apache Pulsar is a distributed pub-sub messaging system. It is designed to handle high-performance, low-latency streaming data, providing a highly available, fault-tolerant, and scalable messaging system that can handle large amounts of data. Pulsar organizes topics into namespaces and supports multiple subscriptions per topic, allowing for flexibility in data access. It also has built-in stream processing framework called Pulsar Functions, which allows you to easily process and analyze data streams in real-time.
Apache Kafka is a distributed log-based message broker. It is designed to handle high-throughput and low-latency data streaming. Kafka is based on the publish-subscribe pattern, where data is written to topics and read by consumers. It stores data in a fault-tolerant way by replicating data across multiple nodes, and allows for horizontal scalability by adding more nodes to a cluster as your traffic grows. Kafka also provides a stream processing library called Kafka Streams and KSQL for stream processing.
Here is a comparison of Apache Pulsar and Apache Kafka on the basis of features in tabular format:
|
Feature |
Apache Pulsar | Apache Kafka |
| Multi-tenancy | Yes | No |
| Low Latency | Yes | Yes |
| Durability | Yes | Yes |
| Scalability | Yes | Yes |
| High-throughput | Yes | Yes |
| Stream Processing | Yes | Yes |
| Multi-language support | Yes | Yes |
| Security | Yes | Yes |
| Tiered storage | Yes | No |
| Distributed | Yes | Yes |
| Tiered storage | Yes | No |
| Geo-replication | Yes | No |
| Time-based retention policies | Yes | No |
| Fault-tolerance | High | High |
| Stream Processing | High | High |
| Connector support | Good | Good |
| Ease of use | Moderate | Moderate |
| Security | Good |
Good |
Here is a comparison of Apache Pulser vs apache Kafka on the basis of architecture in tabular format:
| Feature | Apache Pulsar | Apache Kafka |
|---|---|---|
| Architecture | Distributed Pub-Sub messaging system | Distributed log |
| Data Model | Topics with multiple subscriptions | Topics with partitions |
| Storage | Tiered storage with BookKeeper | Log-based storage |
| Stream Processing | Built-in stream processing framework (Pulsar Functions) | Kafka Streams, KSQL |
| Scale-out | Scale out by adding new nodes | Scale out by adding new nodes or increasing partition count |
| Durability | Automatic replication of data across multiple nodes | Automatic replication of data across multiple nodes |
| Security | Authentication, authorization, and encryption | Authentication, authorization, and encryption |
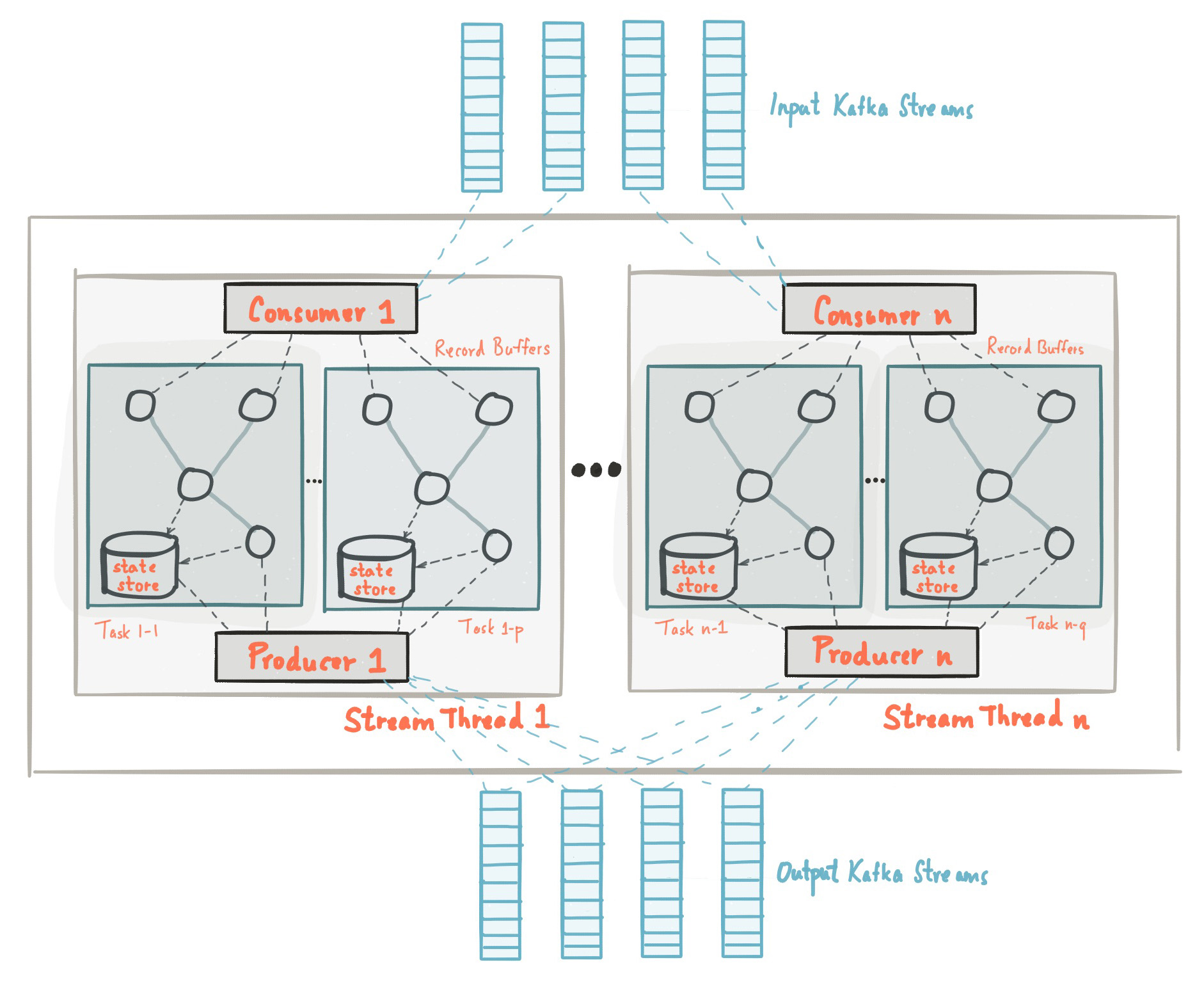
Apache Kafka Architecture Diagram
Apache Pulser Architecture Diagram
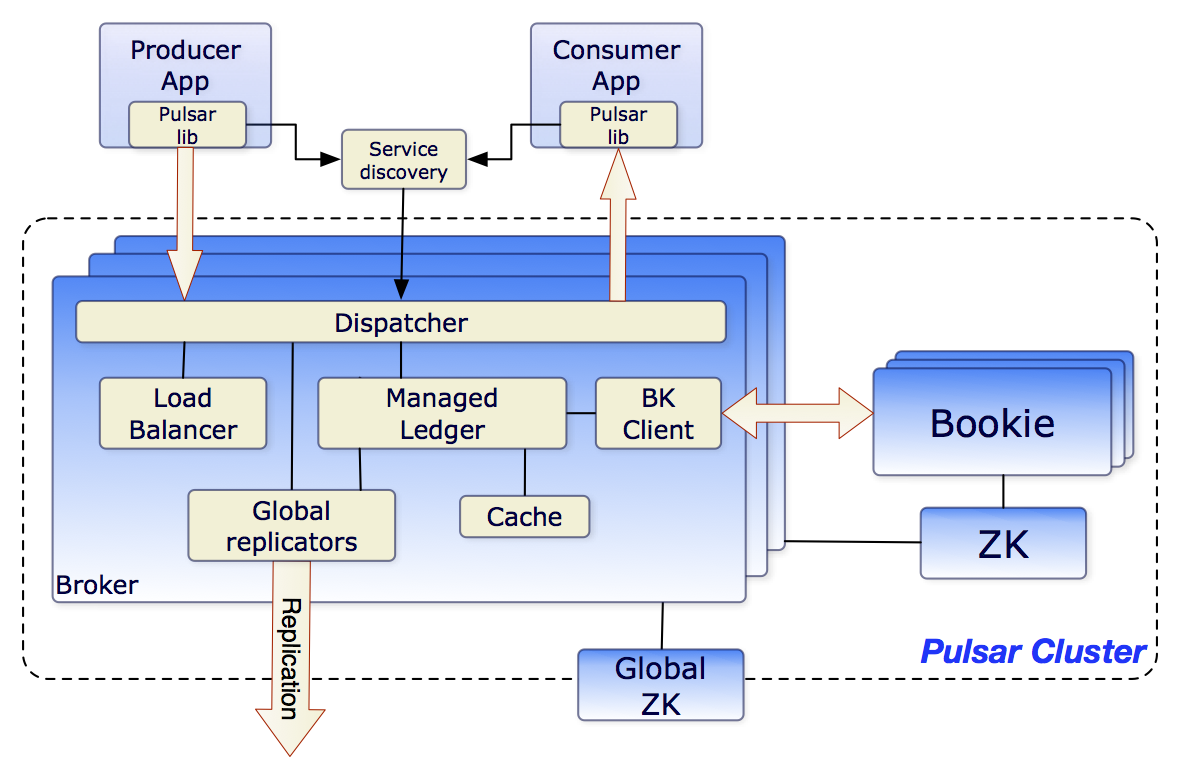
Apache Pulsar and Apache Kafka are both distributed systems, but their architecture is different. Pulsar is a distributed pub-sub messaging system that is designed to handle high-performance, low-latency streaming data, while Kafka is a distributed log that can handle high-throughput and low-latency data streaming. Pulsar has built-in stream processing framework, whereas Kafka has its own stream processing library called Kafka Streams and KSQL. They both have similar scale-out capabilities, durability, and security features.
here are some more details about the main differences between Apache Pulsar and Apache Kafka:
- Data Model: Pulsar’s data model is based on topics with multiple subscriptions, while Kafka’s data model is based on topics with partitions. This allows Pulsar to provide more flexibility in data access and better support for multi-tenancy.
- Storage: Pulsar uses a tiered storage model with BookKeeper, which allows for more efficient storage of large amounts of data. Kafka, on the other hand, uses a log-based storage model, which is simpler but less efficient for storing large amounts of data.
- Stream Processing: Pulsar has a built-in stream processing framework called Pulsar Functions, which allows you to easily process and analyze data streams in real-time. Kafka, on the other hand, has a separate stream processing library called Kafka Streams and KSQL, which allows you to process data streams using SQL-like operations.
- Scale-out: Both Pulsar and Kafka can be scaled out by adding new nodes to a cluster, but Pulsar also allows for more fine-grained control over how data is distributed and replicated across the cluster.
- Durability: Both Pulsar and Kafka provide automatic replication of data across multiple nodes to ensure data durability and availability.
- Security: Both Pulsar and Kafka provide support for authentication, authorization, and encryption to ensure secure data transfer and storage.
- Use Case: Pulsar is well-suited for use cases that require low-latency, high-throughput messaging and stream processing, such as IoT, financial services, and real-time analytics. Kafka, on the other hand, is well-suited for use cases that require handling large amounts of data in real-time, such as log aggregation, real-time data pipelines, and streaming data analytics.
Use cases where Apache Pulsar and Apache Kafka are commonly used:
Apache Pulsar:
- IoT: Pulsar’s low-latency and high-throughput capabilities make it well-suited for handling large amounts of data from IoT devices in real-time.
- Financial Services: Pulsar’s built-in stream processing framework and low-latency messaging make it well-suited for use cases such as real-time financial analytics and trading systems.
- Real-time Analytics: Pulsar’s ability to handle large amounts of data in real-time and support for stream processing make it well-suited for use cases such as real-time data warehousing and analytics.
- Multi-tenancy: Pulsar’s support for multi-tenancy allows it to handle data from multiple customers or organizations in a single cluster, making it well-suited for use cases such as cloud messaging and streaming data as a service.
Apache Kafka:
- Log Aggregation: Kafka’s ability to handle large amounts of data in real-time and support for log-based storage make it well-suited for use cases such as log aggregation and analysis.
- Real-time Data Pipelines: Kafka’s ability to handle large amounts of data in real-time and support for stream processing make it well-suited for use cases such as real-time data pipelines and ETL.
- Streaming Data Analytics: Kafka’s ability to handle large amounts of data in real-time and support for stream processing make it well-suited for use cases such as real-time data warehousing and analytics.
- Event-Driven Architecture: Kafka’s pub-sub model allows it to handle and process events in real-time, making it well-suited for use cases such as event-driven microservices and real-time data integration.
It’s worth noting that both Apache Pulsar and Apache Kafka are powerful tools for handling streaming data and have their own strengths, the choice of which one to use depends on the specific use case and the requirements of your application.