“Streaming into the Future: A Deep Dive into Apache Kafka’s Capabilities”
Apache Kafka is an open-source, distributed streaming platform used to build real-time data pipelines and streaming applications. It was developed by LinkedIn and later donated to the Apache Software Foundation in 2011.
Kafka is designed to handle high-throughput, low-latency, and fault-tolerant data streams. and can handle millions of events per second and can handle terabytes of data without any data loss.
Kafka’s architecture is based on a publish-subscribe model, in that producers write data to topics, and consumers read data from topics. Topics are divided into partitions, and each partition is a ordered, immutable sequence of records that is stored on a Kafka broker. Each record in a partition is assigned a unique offset, which is used to identify the position of the record in the partition.

Kafka uses a distributed commit log to store all the data that is written to a topic. This allows for fault-tolerance and allows the system to handle node failures without any data loss. The data in a topic is also replicated across multiple nodes, which provides data durability and high availability.
Kafka also provides a range of features such as:
- Data Compression: Kafka supports data compression to reduce the amount of storage and bandwidth needed to transmit data.
- Data Retention: Kafka allows you to configure how long to retain data in a topic and provides options to automatically delete older data or to compact data to reduce storage requirements.
- Stream Processing: Kafka provides a stream processing API that allows you to perform real-time data processing on streams of data.
- Connectors: Kafka provides a range of connectors that allow you to easily integrate with external systems such as databases, message queues, and data stores.
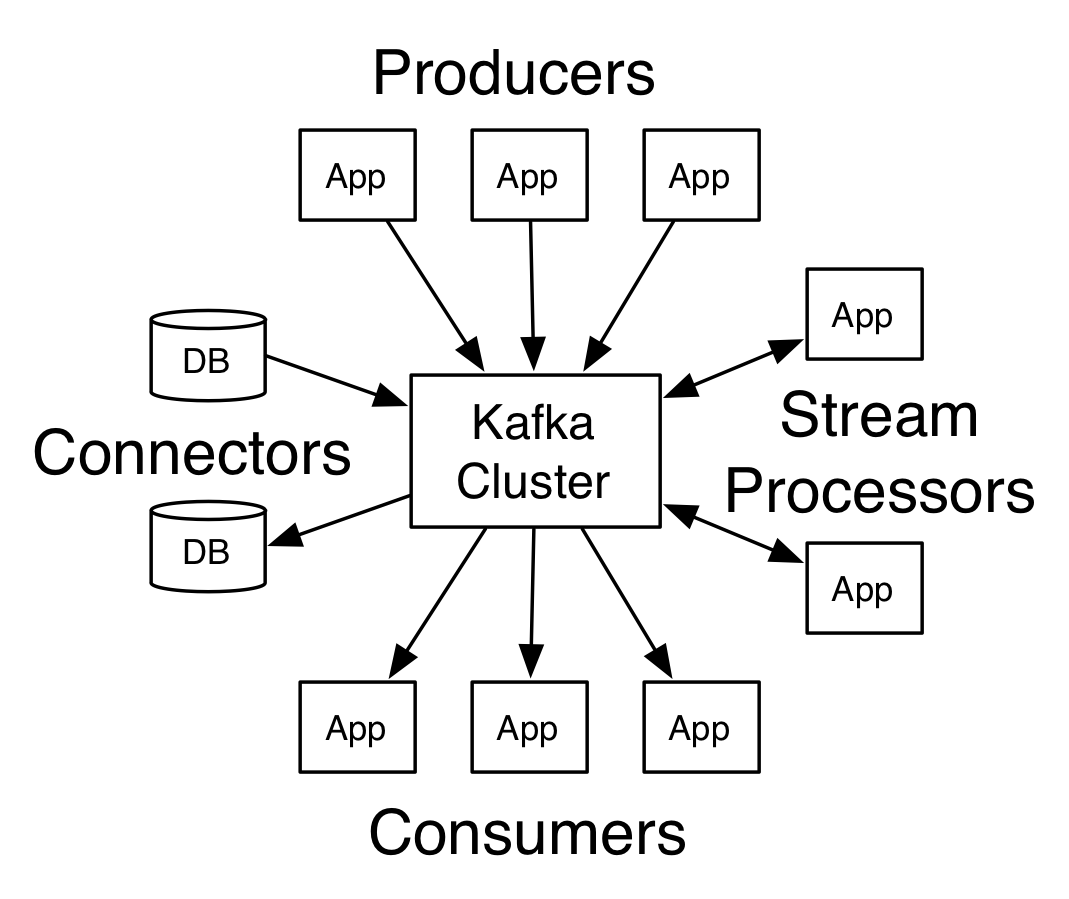
Kafka also provides several advanced features, such as:
- Replication: Kafka replicates data across multiple brokers to provide data durability and high availability. Replicas are used to handle broker failures and to provide load balancing.
- Partitioning: Kafka allows you to partition topics, which allows you to scale the number of consumers and to distribute data across multiple machines.
- Compaction: Kafka provides a feature called log compaction, which allows you to retain only the latest version of a record in a partition and to delete older versions of a record automatically.
- Security: Kafka provides a number of security features, such as authentication, authorization, and encryption, to secure data in transit and at rest.
- Monitoring and Management: Kafka provides a number of tools and APIs for monitoring and managing a Kafka cluster, such as Kafka Manager,
Apache Kafka provides a number of APIs for producing, consuming, and managing data streams. These APIs include:
- Producer API: The Producer API allows you to write data to a topic. It provides a simple and synchronous interface for sending records to a topic. The API allows you to specify the topic, key, and value of a record, as well as other properties such as the partition and timestamp.
- Consumer API: The Consumer API allows you to read data from a topic. It provides a simple and synchronous interface for subscribing to topics and consuming records. The API allows you to specify the topic, group ID, and other properties such as the offset and partition.
- Streams API: The Streams API allows you to perform real-time data processing on streams of data. It provides a simple and high-level API for consuming and producing data streams, as well as for performing operations such as filtering, mapping, and aggregation.
- Connect API: The Connect API allows you to easily integrate Kafka with other systems such as databases, message queues, and data stores. It provides a simple and extensible API for creating and managing connectors.
- Admin API: The Admin API allows you to manage and configure a Kafka cluster. It provides a simple and programmatic interface for creating, updating, and deleting topics, as well as for managing other cluster-level configurations.
Here is an example of a sample Kafka producer API in Java:
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<String, String>("topicName", "key", "value"));
producer.close();
In this example, a Kafka producer is created and configured with a set of properties such as the bootstrap servers and serializers for key and value. Then it sends a record to a topic named “topicName” with key “key” and value “value”.
The consumer and other APIs work similarly with the necessary modification.
Kafka is widely used in many use cases such as real-time data pipelines, event-driven architectures, log aggregation, and stream processing. It’s also widely used by many companies for example Netflix, Uber, and LinkedIn.